Notícias
RÁDIO CIÊNCIA
Ferramenta identifica linguagem ofensiva nas redes sociais

Uma das discussões mais acaloradas dos últimos meses tem sido a regulamentação das Redes Sociais Digitais no Brasil. São dois os fatores que impulsionam esse debate: o papel central que essas plataformas ocuparam na articulação dos atos golpistas do 8 de Janeiro de 2023, e a falta de políticas efetivas de combate aos discursos de ódio e notícias falsas.
📱Siga o Canal da Universidade FM no WhatsApp👆🏼
A pesquisa “Detecção Automática de Linguagem Ofensiva: Uma Análise do Uso de Algoritmos Tradicionais de AM e Técnicas de PLN na Detecção de Linguagem Ofensiva” atua nesse cenário, a partir da construção de uma ferramenta para facilitar a identificação de postagens consideradas hostis.
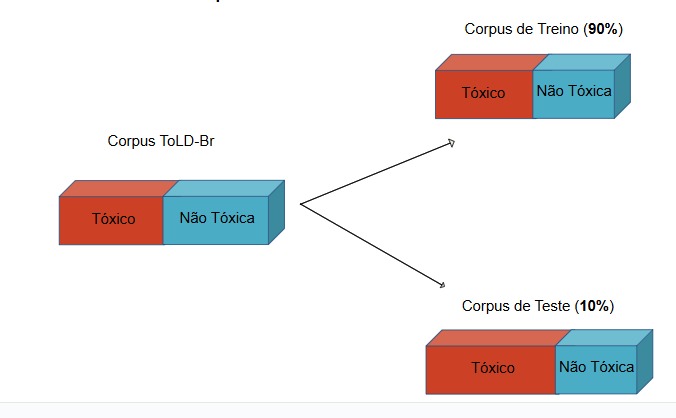
Divisão do corpus em treino e teste
O projeto é conduzido pelo estudante do Curso Técnico em Informática, do Instituto Federal de Educação, Ciência e Tecnologia do Maranhão (IFMA) - Campus Barra do Corda, a 462 quilômetros de São Luís, Renner Carneiro Araújo, e utiliza os chamados Algoritmos de Aprendizado de Máquina, ou seja, programas que conseguem fazer previsões ou categorizar informações a partir de uma base de dados.
Outra técnica aplicada é o Processamento de Linguagem Natural, que permite à inteligência artificial a capacidade de gerar, interpretar e entender a linguagem humana.
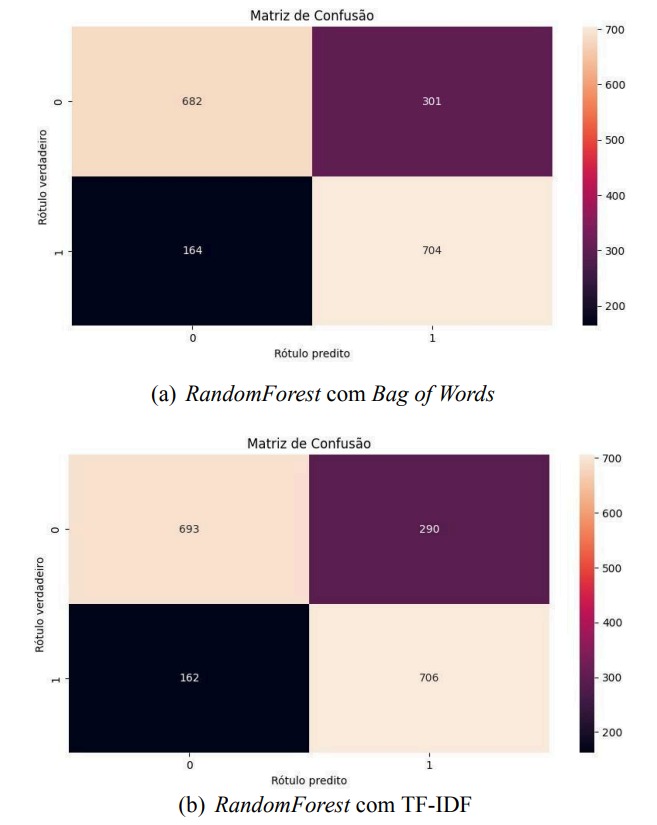
Matriz de confusão do melhor modelo nas duas amostras de tokens utilizados no projeto
Como auxílio nesse processo, o pesquisador separou postagens consideradas ofensivas feitas no X, antigo Twitter. Elas foram convertidas em números para leitura do algoritmo, com o objetivo de identificar os padrões da linguagem ofensiva.
“Essa IA poderá ser utilizada, tanto por grandes redes sociais que lidam diariamente com grandes volumes de dados, quanto por plataformas menores, ou fóruns que possuam seção de comentários. Isso se dá, porque o diferencial do Aprendizado de Máquina é a leveza computacional. Enquanto modelos baseados em Redes Neurais Profundas exigem grande poder computacional, os algoritmos tradicionais do aprendizado de máquina conseguem detectar a linguagem ofensiva de forma eficiente em ambientes mais simples”, disse Renner Araújo.
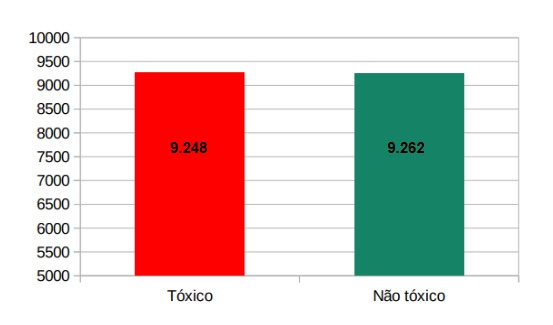
Gráfico do corpus Told-br com a quantidade de tweets tóxicos e não tóxicos
Com orientação do Prof. de Informática do IFMA-Barra do Corda, Jeziel Costa Marinho, o projeto tem apoio da Fundação de Amparo à Pesquisa e ao Desenvolvimento Científico e Tecnológico do Maranhão (FAPEMA), apresentado durante a 77ª edição da Reunião Anual da Sociedade Brasileira para o Progresso da Ciência (SBPC).
Ouça!
🌎 | Instagram | CANAL WHATSAPP | X | Spotify | Spotify Playlists |
Deezer | Amazon Music | Apple Podcasts
São Luís – MA
2025